Python 协程和事件循环
1 前言
Python 标准库 asyncio 是我目前接触过的最难理解的 Python 库,它的实现使用了太多我不太熟悉的东西:协程、事件循环、多路 I/O 复用……
我对这些概念的认识基本都是停留在知道有这么个东西,大概有什么用上,当真的遇到这些东西的使用的时候,就抓了瞎。
然而,运气很好的是,随着协程使用的普及(不只是 Python),现在可以在网上找到很多相关的文章,借助这些文章,我终于大致明白了这个库背后的部分工作原理。
- @2020-01-20:重新找了个时间换了个角度研究了一下事件循环和协程,感兴趣的可以看一下 ☞ 事件循环和协程
2 协程
首先需要明白的是,协程不是 Python 独有的功能,因为协程通常是在 语言 层面上实现的功能,因此,只要有需要,各个语言都有可能实现这一功能。
而在 Python 中,协程虽然是借助 生成器 实现的(有关生成器的介绍可以看这篇博客:Python 生成器),但是在使用时一定要分清这两个概念。
引用 David Beazley 在 PyCon 2009 的课程 A Curious Course on Coroutines and Concurrency 中的观点来说的话就是:
- 生成器生产数据而协程消费数据,同时,协程和迭代无关
举例来说,下面这段代码可以创建用于匹配包含指定 pattern 的句子的协程:
def grep(pattern): print("Looking for %s" % pattern) while True: line = yield if pattern in line: print(line)
代码的执行测试:
>>> g = grep("python") >>> next(g) Looking for python >>> g.send("Yeah, but no, but yeah, but no") >>> g.send("A series of tubes") >>> g.send("python generators rock!") python generators rock!
可以看到,使用协程时我们并不关心协程的返回值,而是不断的向协程传输数据进行处理。
PS:假如你不理解这段代码,可以先看看有关于 生成器对象 的内容
3 async & await
在 Python 中调用协程对象1的 send() 方法时,第一次调用必须使用参数 None, 这使得协程的使用变得十分麻烦。
因此,我们可以借助 Python 自身的特性来避免这一问题,比如,创建一个装饰器:
def coroutine(func): def start(*args, **kwargs): cr = func(*args, **kwargs) cr.send(None) return cr return start
当我们用这个装饰器装饰协程时,每次创建新的协程对象它就会自己帮我们调用 send(None), 由于这个装饰器使用的很频繁,因此,从 Python3.5 开始,这个装饰器就演变为了关键字 async.
对于关键字 await 来说,我们可以把它看做 yield from 的替代,而 yield from 的作用大致和下面的循环相同:
yield from iterator for x in iterator: yield x
4 事件循环
看到事件循环的时候我首先想到的是 GUI 程序编程中的那种事件/消息循环,通过注册回调的方式,由事件循环获取事件并调用回调处理事件。
在 GUI 编程中,事件的获取可以由 操作系统 这样的低层设施完成,然后将事件放到应用程序的事件队列中,编写程序时,只需要考虑从队列中获取处理事件。
然而在 asyncio 中,这个事件队列需要由自己来维护,而这篇博客的主要内容,就是学习这个事件队列(事件循环)维护方式。
注: 这一节剩下的内容算是我的探索过程,有兴趣的可以看一下,急着看结论的可以到下一节。
首先是一篇 掘金 翻译的文章,文章中实现了一个简单的事件循环,当然,这个事件循环很不完善:
点击查看代码
import datetime import heapq import types import time class Task: """Represent how long a coroutine should before starting again. Comparison operators are implemented for use by heapq. Two-item tuples unfortunately don't work because when the datetime.datetime instances are equal, comparison falls to the coroutine and they don't implement comparison methods, triggering an exception. Think of this as being like asyncio.Task/curio.Task. """ def __init__(self, wait_until, coro): self.coro = coro self.waiting_until = wait_until def __eq__(self, other): return self.waiting_until == other.waiting_until def __lt__(self, other): return self.waiting_until < other.waiting_until class SleepingLoop: """An event loop focused on delaying execution of coroutines. Think of this as being like asyncio.BaseEventLoop/curio.Kernel. """ def __init__(self, *coros): self._new = coros self._waiting = [] def run_until_complete(self): # Start all the coroutines. for coro in self._new: wait_for = coro.send(None) heapq.heappush(self._waiting, Task(wait_for, coro)) # Keep running until there is no more work to do. while self._waiting: now = datetime.datetime.now() # Get the coroutine with the soonest resumption time. task = heapq.heappop(self._waiting) if now < task.waiting_until: # We're ahead of schedule; wait until it's time to resume. delta = task.waiting_until - now time.sleep(delta.total_seconds()) now = datetime.datetime.now() try: # It's time to resume the coroutine. wait_until = task.coro.send(now) heapq.heappush(self._waiting, Task(wait_until, task.coro)) except StopIteration: # The coroutine is done. pass @types.coroutine def sleep(seconds): """Pause a coroutine for the specified number of seconds. Think of this as being like asyncio.sleep()/curio.sleep(). """ now = datetime.datetime.now() wait_until = now + datetime.timedelta(seconds=seconds) # Make all coroutines on the call stack pause; the need to use `yield` # necessitates this be generator-based and not an async-based coroutine. actual = yield wait_until # Resume the execution stack, sending back how long we actually waited. return actual - now async def countdown(label, length, *, delay=0): """Countdown a launch for `length` seconds, waiting `delay` seconds. This is what a user would typically write. """ print(label, 'waiting', delay, 'seconds before starting countdown') delta = await sleep(delay) print(label, 'starting after waiting', delta) while length: print(label, 'T-minus', length) waited = await sleep(1) length -= 1 print(label, 'lift-off!') def main(): """Start the event loop, counting down 3 separate launches. This is what a user would typically write. """ loop = SleepingLoop(countdown('A', 5), countdown('B', 3, delay=2), countdown('C', 4, delay=1)) start = datetime.datetime.now() loop.run_until_complete() print('Total elapsed time is', datetime.datetime.now() - start) if __name__ == '__main__': main()
可能的执行结果是这样的:
A waiting 0 seconds before starting countdown B waiting 2 seconds before starting countdown C waiting 1 seconds before starting countdown A starting after waiting 0:00:00.001000 A T-minus 5 C starting after waiting 0:00:01.000057 C T-minus 4 A T-minus 4 B starting after waiting 0:00:02.000115 B T-minus 3 C T-minus 3 A T-minus 3 B T-minus 2 C T-minus 2 A T-minus 2 B T-minus 1 C T-minus 1 A T-minus 1 B lift-off! C lift-off! A lift-off! Total elapsed time is 0:00:05.003286
在这段代码中我获得的重要信息:事件循环取出协程执行后,如果协程未执行完,会将协程再次放到事件/协程队列中。
当然,这是显而易见的,自己思考也大概能够想到这一点。
通过这样的想法可以大致理解如下的代码:
import asyncio import time async def say_after(delay, what): await asyncio.sleep(delay) print(what) async def main(): print(f"started at {time.strftime('%X')}") await say_after(1, 'hello') await say_after(2, 'world') print(f"finished at {time.strftime('%X')}") asyncio.run(main())
对于这一段代码来说,不断取出执行 main() 的时间花费大概是 3 秒,而事实也是如此。
当时我觉得差不多理解了 asyncio 的工作原理的时候,我看到了这样一段代码:
async def main(): task1 = asyncio.create_task( say_after(1, 'hello')) task2 = asyncio.create_task( say_after(2, 'world')) print(f"started at {time.strftime('%X')}") # Wait until both tasks are completed (should take # around 2 seconds.) await task1 await task2 print(f"finished at {time.strftime('%X')}")
这段代码的执行时间是 2 秒,也就是说,在创建 Task 的过程中,创建的 Task 被直接加入 事件循环 了,但是,这里大概还可以用前面的想法理解,直到我做了这样的修改:
import asyncio import time async def get_after(delay, what): await asyncio.sleep(delay) return what async def main(): print(f"started at {time.strftime('%X')}") task1 = asyncio.create_task(get_after(1, 'hello')) task2 = asyncio.create_task(get_after(2, 'world')) t2 = await task2 t1 = await task1 print(t1, t2) print(f"finished at {time.strftime('%X')}") asyncio.run(main())
这段代码中,第一个任务比第二个任务先完成,但是第一个任务排在第二个任务后面,同时,t1 和 t2 都获得了正确的返回值。
也就是说,两个任务异步完成的同时,还可以按照同步的顺序将值返回。
Oh!!!我的大脑开始晕了,我已经不建议你阅读这一节剩下的内容。
然后,我看到了微信上的文章 深入理解 Python 异步编程(上),其中的一部分代码:
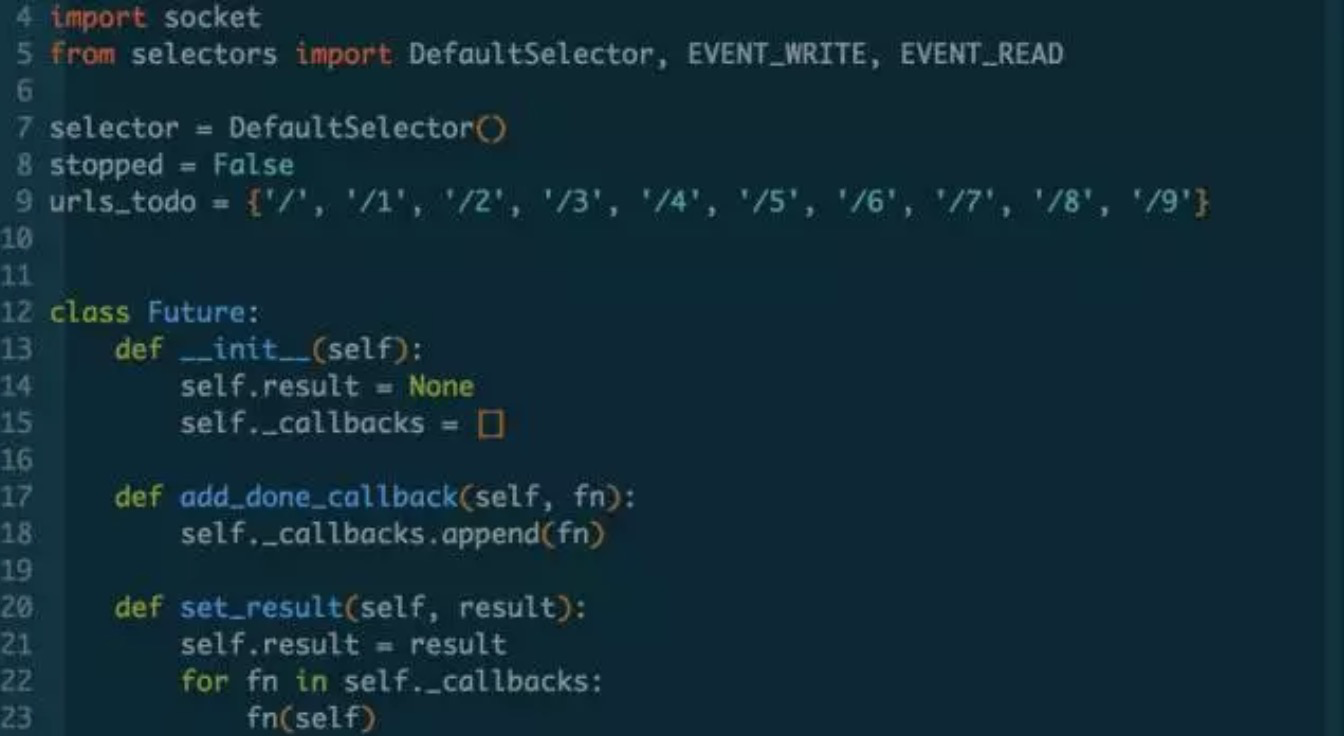
Oh!!!yes!!!我们可以将协程的执行结果保存!!!
同时,我还了解到 Future 的源码中存在这样的代码:
def __iter__(self): if not self.done(): yield self return self.result()
其实,到了这里,我离真相已经不远了,但是,由于我在脑内建立了一个错误的印象: asyncio 内部的事件循环是同时保存了所有的协程的。
导致,我对 asyncio 工作原理的理解陷入僵局:
- 所有协程都在事件循环中
- 当其中某个事件执行完成后,再次调度时,就会获得它的返回值
- 当它的返回值被获取,那么,就不能再次获取返回值了
也就是说,对于下面的代码,我们要保证 val 可以获取 future 的返回值:
val = yield from future
然后我失败了,我在寝室里走过来走过去,用 Google 搜索各种资料,都没能解决我的问题,思维进入了死角。
直到结合源码阅读了一篇博客!
5 asyncio 的事件循环
asyncio 中的事件循环不生产值,但是 返回 值, 返回值是协程的执行结果:
async def coro1(): for i in range(10): val = yield return 10 async def coro2(): val = await coro1()
上面这段代码中的 coro2 大致上等价于:
async def coro2(): for i in range(10): # coro1 val = yield # coro1 val = 10 # coro1 return 10
特别是代码中的 return, 这在 Python2 中是不允许的,但是为了方便,Python3 中加入了这一特性。
然后,我们需要通过下面这段代码来理解 asyncio 内部的事件调度:
import asyncio import time async def get_after(delay, what): await asyncio.sleep(delay) return what async def main(): print(f"started at {time.strftime('%X')}") task1 = asyncio.create_task(get_after(1, 'hello')) task2 = asyncio.create_task(get_after(2, 'world')) t2 = await task2 t1 = await task1 print(t1, t2) print(f"finished at {time.strftime('%X')}") asyncio.run(main())
这段代码中,首先创建了两个 Task, 我们可以看一下 Task 的构造函数:
class Task(futures.Future): def __init__(self, coro, *, loop=None): ... self._loop.call_soon(self._step) ...
可以看到,Task 在创建的时候就会通过 loop.call_soon 将 Task 放入事件循环。同时,Task 可以被用在 await(yield from),
说明它是一个可迭代对象,也就是实现了 __iter__ 方法:
class Future: def __await__(self): if not self.done(): ... yield self # This tells Task to wait for completion. if not self.done(): raise RuntimeError("await wasn't used with future") return self.result() # May raise too. __iter__ = __await__ # make compatible with 'yield from'.
现在,这段代码中的 main() 可以改造为:
async def main(): print(f"started at {time.strftime('%X')}") task1 = asyncio.create_task(get_after(1, 'hello')) task2 = asyncio.create_task(get_after(2, 'world')) if not task2.done(): yield task2 assert task2.done() t2 = task2.result() if not task1.done(): yield task1 assert task1.done() t1 = task1.result() print(t1, t2) print(f"finished at {time.strftime('%X')}")
对于 main() 来说,我们需要保证在 task2 和 task1 执行完成之前不会调度它自己,如果将 main() 一直放在事件循环中,那么是无法实现这一点的。
也就是说,我们在执行到 task2 或 task1 的位置后,如果 task2 或 task1 没有执行完成,就需要将 main() 从事件循环中取出,等到 task2 或 task1 执行完成后在继续执行。
当我们通过 asyncio.run(main()) 开始执行程序时,main() 会被 Task 包装,然后调用 Task 的方法 _step():
def _step(self, exc=None): try: if exc is None: # We use the `send` method directly, because coroutines # don't have `__iter__` and `__next__` methods. result = coro.send(None) else: result = coro.throw(exc) except StopIteration as exc: if self._must_cancel: ... else: self.set_result(exc.value) except futures.CancelledError: ... except Exception as exc: ... except BaseException as exc: ... else: blocking = getattr(result, '_asyncio_future_blocking', None) if blocking is not None: # Yielded Future must come from Future.__iter__(). if result._loop is not self._loop: ... elif blocking: ... else: result._asyncio_future_blocking = False result.add_done_callback(self._wakeup) ... elif result is None: # Bare yield relinquishes control for one event loop iteration. self._loop.call_soon(self._step) ...
假如调用方法 _step() 的时候 task2 还没有执行完成,那么就会执行 yield task2, 在获取到 task2 之后,就会执行操作:
result.add_done_callback(self._wakeup)
我们可以看一下相关的代码:
def add_done_callback(self, fn, *, context=None): if self._state != _PENDING: self._loop.call_soon(fn, self, context=context) else: ... self._callbacks.append((fn, context)) def _wakeup(self, future): try: future.result() except Exception as exc: # This may also be a cancellation. self._step(exc) else: self._step() self = None # Needed to break cycles when an exception occurs.
这个过程中,Task(main) 的 _wakeup 方法成为了 task2 的回调,而自身从事件循环中取出。
然后,创建 Task 的过程中,task1 和 task2 已经被加入事件循环,加入调用它们返回的是 Task(Future), 就重复之前的过程,否则返回 None 执行:
elif result is None: # Bare yield relinquishes control for one event loop iteration. self._loop.call_soon(self._step)
即:再次将自己放入事件循环。
当 Task 包裹的协程执行完成时,会抛出 StopIteration 异常,执行如下代码:
except StopIteration as exc: if self._must_cancel: ... else: self.set_result(exc.value) def __schedule_callbacks(self): callbacks = self._callbacks[:] if not callbacks: return self._callbacks[:] = [] for callback, ctx in callbacks: self._loop.call_soon(callback, self, context=ctx) def set_result(self, result): if self._state != _PENDING: raise exceptions.InvalidStateError(f'{self._state}: {self!r}') self._result = result self._state = _FINISHED self.__schedule_callbacks()
可以看到,执行 set_result 的时候会执行 callbacks 中的回调,而在之前的操作中,已经将 Task(main) 的 _wakeup 放入回调,也就是说,将要执行:
def _wakeup(self, future): try: ... except Exception as exc: ... else: self._step() # !!! ...
现在,我们恢复了 Task(main) 的正常调度,同时也将执行完成的 Task 从事件循环中取出。
That's all!
6 结语
最后想了下,asyncio 的事件循环其实并不复杂,关键点在于:
- 如果在执行
otask的过程中遇到await itask语句,如果itask还未完成,就将otask从事件循环中取出,并将可以唤醒自身的方法放到itask的回调中 - 当
itask执行完成后,执行itask的所有回调,唤醒otask并将itask从事件循环取出
搞清楚这个问题花了不少的时间,而且现在还不能说是完全正确,真是复杂的问题……
这篇博客写的很乱,有机会的话整理一下吧 @_@
7 参考链接
- 深入理解 Python 异步编程(上)
- 协程、 事件驱动介绍 - W-D - 博客园
- gold-miner/how-the-heck-does-async-await-work-in-python-3-5.md at master · xitu/gold-miner
- 从一道题浅说 JavaScript 的事件循环 · Issue #61 · dwqs/blog
- Event loop - Wikipedia
- atotic/event-loop: event loop docs
- 理解 Python asyncio | 三点水
- :A Curious Course on Coroutines and Concurrency
- Coroutine - Wikipedia