Java 核心集合接口
目录
1 简介
除了 C 语言以外,我学过的语言基本上都封装了常用的 数据结构 方便使用。
Java 同样封装了这些常用的数据结构,但是由于 Java 的语言机制的原因, Java 提供这些数据结构的多种实现。
虽然实现很多, 但不同的实现之间主要是 实现算法 的区别,使用上,只要只要掌握了 共同 的特性,剩下的就好处理的多了。
核心集合接口之间的关系图:
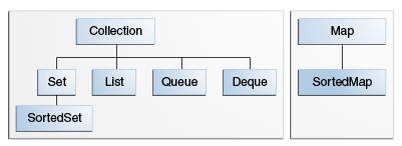
注: 由于还不是很熟悉 Java8, 所以本篇博客不会涉及集合的 聚合操作.
2 Collection
Collection 通常用于保存一组对象,保存的这些对象称为它的 元素 或 成员.
虽然 Collection 接口没有具体的实现,但是所有通用集合类型实现都有一个带 Collection 参数的 构造函数.
List<String> list = new ArrayList<String>(collection);
2.1 Collection 基本操作
Collection 常用的基本操作方法有:
| 方法 | 作用 |
|---|---|
int size() |
获取集合的大小 |
boolean isEmpty() |
判断集合是否为空 |
boolean contains(Object element) |
判断集合中是否存在指定元素 |
boolean add(E element) |
添加指定元素到集合中 |
boolean remove(Object element) |
从集合中移除指定元素,如果指定元素不存在就返回 false |
Iterator<E> iterator() |
获取此集合中元素的迭代器 |
这些操作的使用应该不需要我说明了,十分简单明了。
2.2 Collection 遍历操作
除去 聚合操作 的话,用于遍历 Collection 的方式有两种:
最常用的可能是 for-each 循环了,也很简单:
for (Object o : collection) System.out.println(o);
另外一个不是很常用的就是 Iterators, Iterators 允许你遍历整个集合并有选择的删除集合中的元素。
Iterator 接口:
public interface Iterator<E> { boolean hasNext(); E next(); void remove(); //optional }
方法 remove 会删除当前遍历到的元素,因此只能调用一次,不能重复删除。
你可以通过 Collection 的 iterator() 方法来获取该集合的 Iterator 对象。
比如通过这个方法有选择的过滤集合中的元素:
static void filter(Collection<?> collection) { for (Iterator<?> it = collection.iterator(); it.hasNext(); ) if (!cond(it.next())) it.remove(); }
2.3 Collection 批量操作
批量操作 允许我们一次性操作多个元素,以下是批量操作方法:
| 方法 | 作用 |
|---|---|
boolean containsAll(Collection<?> c) |
判断当前集合是否包含指定集合中的所有元素 |
boolean addAll(Collection<? extends E> c) |
将指定集合中的所有元素添加到当前集合 |
boolean removeAll(Collection<?> c) |
根据指定集合移除当前集合中的元素 |
boolean retainAll(Collection<?> c) |
从当前集合中删除所有未包含在指定集合中的元素 |
void clear() |
移除当前集合中的所有元素 |
2.4 Collection 数组操作
通过使用方法 Collection.toArray() 可以将一个 Collection 转换一个数组。
不带参数调用 Collection.toArray() 时返回一个 Object 数组:
Object[] a = c.toArray();
如果集合中的元素只有一种类型,那么你可以指定要返回的数组的类型:
String[] a = c.toArray(new String[0]);
注意,如果集合元素类型为 原始数据类型, 那么对应的参数应该是 包装类数组类型.
比如: new Integer[0]
3 Set
Set 是一个不包含重复元素的 Collection.
实现有:
HashSet- 元素储存在一个哈希表中,性能最好,但是不保证元素的迭代顺序TreeSet- 元素储存在一个红黑树中,元素按值排序,速度比HashSet慢很多LinkedHashSet- 元素储存在一个链表中,元素按添加的属性排序,速度比HashSet慢
Set 的操作和 Collection 基本相同,特殊之处在于如果向 Set 中添加已存在的元素会失败,因为 Set 不允许存在重复的元素。
一些简单的操作:
// 去除重复元素 List<Integer> lst = new ArrayList<Integer>(new HashSet<Integer>(oneList)); // s1, s2 的并集 Set<Type> union = new HashSet<Type>(s1).addAll(s2); // s1, s2 的交集 Set<Type> intersection = new HashSet<Type>(s1).retainAll(s2); // s1, s2 的不相交集 Set<Type> difference = new HashSet<Type>(s1).removeAll(s2);
4 List
List 是一个有序的 Collection.
实现有:
ArrayList- 通常使用的就是这个LinkedList- 在某些情况下可以提供比ArrayList更好的性能
4.1 集合操作
毫无疑问, List 包含继承了所有 Collection 的操作,如添加删除元素等。
特别的, add 和 addAll 默认情况下会将元素添加到集合的 末尾.
4.2 位置访问和搜索操作
get 和 set 可以获取值设置指定位置的元素的值, 而 add, addAll, remove 都有一个可以指定位置的 重载, 允许你指定要操作的元素的位置。
交换两个元素的位置:
public static <E> void swap(List<E> a, int i, int j) { E tmp = a.get(i); a.set(i, a.get(j)); a.set(j, tmp); }
indexOf 和 lastIndexOf 获取指定元素在集合中 首次 和 最后一次 出现的位置。
4.3 迭代器
List 除了继承自 Collection 的迭代器以外,还提供了一个功能更强大的迭代器 ListIterator.
ListIterator 继承了 Iterator 的方法 hasNext, next 和 remove, 还提供了新的方法 hasPrevious 和 previous.
也就是说,通过 ListIterator 你可以向前向后迭代 List 中的元素。
for (ListIterator<Type> it = list.listIterator(list.size()); it.hasPrevious(); ) { Type t = it.previous(); ... }
特别的, ListIterator 有两种创建方式, 默认情况下初始位置位于 List 头部, 也可以指定初始的索引。
如果倒序迭代的话,应该将索引设置为 List 的 大小, 因为 previous 将索引 减一, List.size() - 1 正好是最后一个元素的位置。
4.4 范围视图操作
List 的方法 subList(int fromIndex, int toIndex) 返回指定范围的 列表视图.
范围指定如下:
for (int i = fromIndex; i < toIndex; i++) { ... }
注: subList 返回的是一个 视图, 所有对这个 视图 的操作都会反应到原列表上
比如,删除指定范围内的所有元素:
list.subList(fromIndex, toIndex).clear();
4.5 列表算法
Collections 提供了一些很有用的算法, 这里列出来:
| 算法 | 作用 |
|---|---|
sort |
排序 |
shuffle |
随机置换列表中的元素 |
reverse |
反转列表 |
rotate |
将列表中的所有元素旋转指定的距离 |
swap |
交换指定列表中指定位置的元素 |
replaceAll |
将所有出现的一个指定值替换为另一个 |
fill |
用指定的值覆盖列表中的每个元素 |
copy |
将源列表复制到目标列表 |
binarySearch |
使用二分查找法在列表中查找指定元素(列表需要排序) |
indexOfSubList |
获取指定元素在子列表中首次出现的位置 |
lastIndexOfSubList |
获取指定元素在子列表中最后一次出现的位置 |
注: 是 Collections 不是 Collection.
5 Queue
Queue 是在处理之前保存元素的 Collection.
除了 Collection 的所有操作以外, Queue 接口还有:
public interface Queue<E> extends Collection<E> { E element(); boolean offer(E e); E peek(); E poll(); E remove(); }
每个 Queue 操作都有两种表现形式:
- 操作失败抛出异常
- 操作失败返回特殊值(
nullorfalse)
| 操作类型 | 抛出异常 | 返回特殊值 |
|---|---|---|
Insert |
add(e) |
offer(e) |
Remove |
remove() |
poll() |
Examine |
element() |
peek() |
队列 的特性是 先进先出.
6 Deque
Deque 是一个 双端队列, 是元素的线性集合,支持在两个端点处插入和移除元素。
Deque 操作:
| 操作类型 | 双端队列头 | 双端队列尾 |
|---|---|---|
Insert |
addFirst(e) offerFirst(e) |
addLast(e) offerLast(e) |
Remove |
removeFirst() pollFirst() |
removeLast() pollLast() |
Examine |
getFirst() peekFirst() |
getLast() peekLast() |
7 Map
Map 是将键映射到值的对象。 不属于 Collection.
Map 的 键 不能重复, 同时每个 键 只能映射一个值。
Map 的实现有: HashMap, TreeMap 和 LinkedHashMap. 它们的行为类似于 HashSet, TreeSet
和 LinkedHashSet.
7.1 Map 基本操作
Map 的基本操作包括以下几个:
| 操作 | 作用 |
|---|---|
put |
将指定的值与此映射中的指定键相关联 |
get |
返回指定键映射到的值,如果此映射不包含键的映射,则返回 null |
containsKey |
如果此映射包含指定键的映射,则返回 true |
containsValue |
如果此映射将一个或多个键映射到指定值,则返回 true |
size |
返回此映射中键 - 值映射的数量 |
isEmpty |
如果此映射不包含键 - 值映射,则返回 true |
List 和 Map 应该是我最常用的两个数据结构, Map 的值可以为一个 List, 通过这种方式间接达成一个 键 映射多个 值.
统计命令行参数的出现频率:
public class Freq { public static void main(String[] args) { Map<String, Integer> m = new HashMap<String, Integer>(); // Initialize frequency table from command line for (String a : args) { Integer freq = m.get(a); m.put(a, (freq == null) ? 1 : freq + 1); } System.out.println(m.size() + " distinct words:"); System.out.println(m); } }
7.2 Map 批量操作
方法 clear 可以清除 Map 中的所有映射关系,而 putAll 可以使用另一个 Map 来更新当前的 Map, 覆盖存在的关系,添加新的关系。
static <K, V> Map<K, V> newAttributeMap(Map<K, V>defaults, Map<K, V> overrides) { Map<K, V> result = new HashMap<K, V>(defaults); result.putAll(overrides); return result; }
7.3 集合视图
通过如下三个方法获取 Map 的 集合视图:
| 方法 | 返回值 |
|---|---|
keySet |
一个 Set 包含 Map 的所有键 |
values |
一个 Collection 包含 Map 的所有值 |
entrySet |
一个 Set 包含 Map 中所有的键值对 |
对这三个方法的返回只进行修改会反应到 Map 上, 对 Map 的修改也会反应到 返回值 上。
通过 Jython 进行的测试:
>>> from java.util import * >>> map = HashMap() >>> map.put(1, 2) >>> map.put(2, 3) >>> map.put(4, 5) >>> key = map.keySet() >>> key [1, 2, 4] >>> key.remove(4) True >>> map {1: 2, 2: 3}
遍历 Map 的每一个键:
for (KeyType key : m.keySet()) System.out.println(key);
根据 键 过滤 Map:
for (Iterator<Type> it = m.keySet().iterator(); it.hasNext(); ) if (it.next().isBogus()) it.remove();
entrySet 常和 Map.Entry 一块使用:
for (Map.Entry<KeyType, ValType> e : m.entrySet()) System.out.println(e.getKey() + ": " + e.getValue());
8 结尾
核心接口中还有 SortedSet 和 SortedMap, 它们都会对内部的元素进行排序,其余行为和它们的父接口基本一致。
在 Python 中,我常用的数据结构对应到 Java 中应该为: ArrayList, HashSet, HashMap 和 LinkedHashMap.
不得不说, Java 的数据结构实现很多,这篇博客只是简单列举出来这些数据结构可以执行的操作,具体的使用还是实践中尝试吧!